scikit-learn release 1.9: better numerics, new core functionality
 Author:
Author:
 Gael Varoquaux
Gael VaroquauxScikit-learn 1.9 release is out, and it comes with solid improvements to many existing estimators, making them faster, more stable, handling missing values, adding GPU support… The release also enhances the estimator displays in notebooks, and introduces a callback mechanism that opens the door to progress bars or advanced monitoring of convergence.
Improvement: Richer HTML views
The improvements that most will easily view are those on the estimator displays.
Since recent versions, the estimator views displayed in notebooks can show the parameters of the estimators (revealed by clicking on the estimator name). Latest release adds a view of the fitted attribute, as visible below:
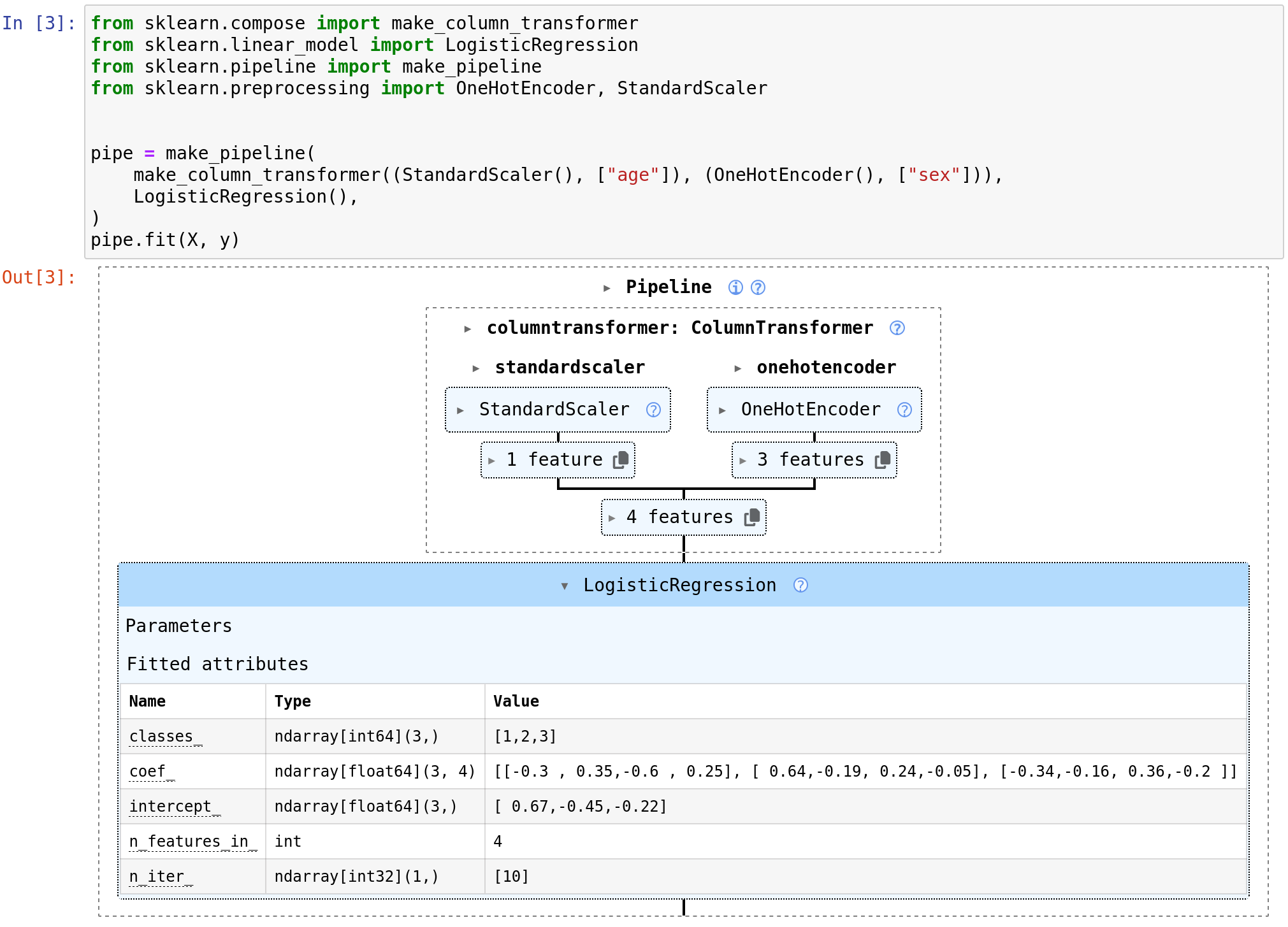
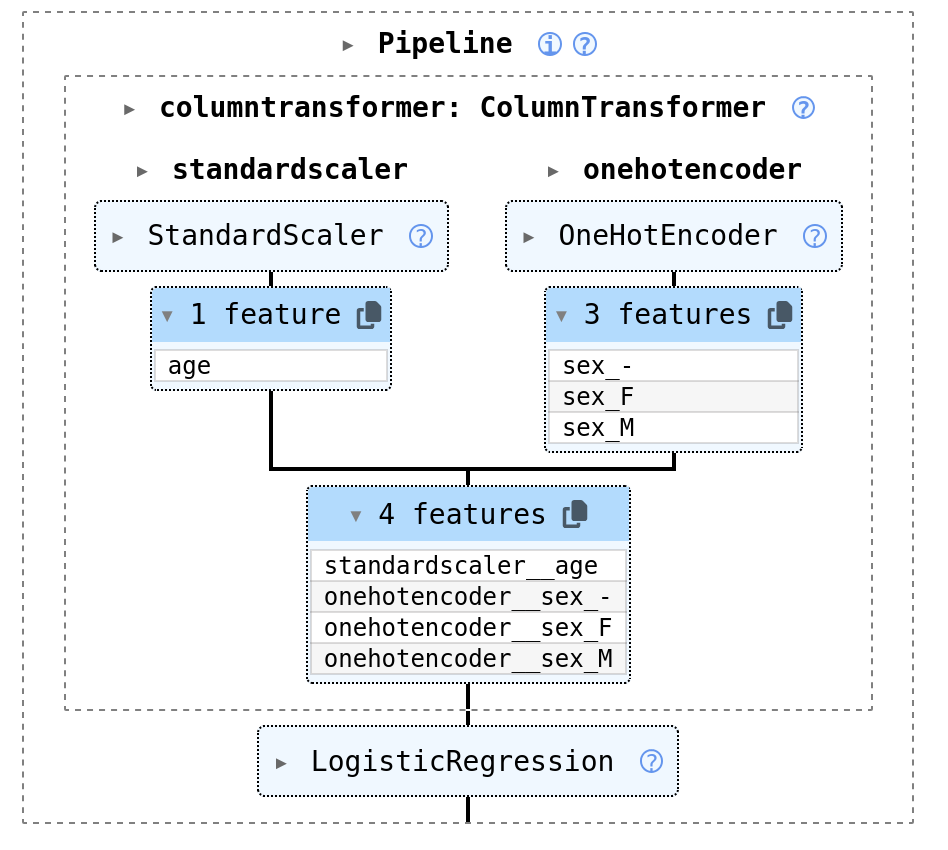
In addition, the ColumnTransformer’s view has been enhanced to help the user understand how features are assembled:
A new promise: Callbacks
Scikit-learn 1.9 comes with a callback mechanism, currently experimental. We spent a lot of time designing it so that it enables many different uses: nested tracking of progress (even in parallel computing) on a variety of measures, early stopping…
The release notes come with an example on how to use these callbacks to monitor scores and to display progress bars – a more advance monitoring example.
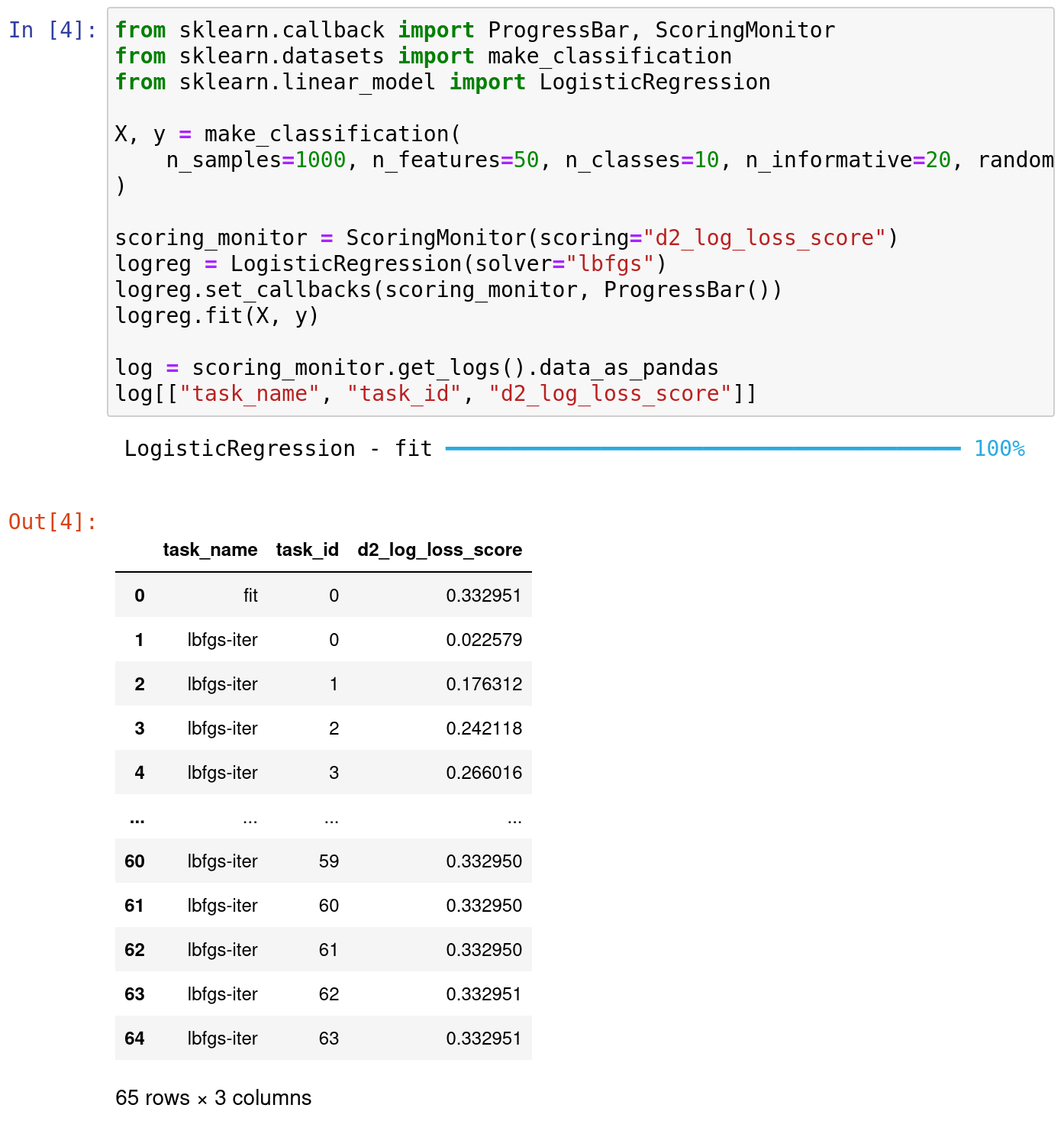
As of today, the callbacks are implemented in logistic regression (with LBFGS solver), the various *SearchCV objects, Pipeline, StandardScaler. The next releases will progressively add callbacks in more and more estimators (this is a place where contributors can help).
Improved statistics and numerics
As users, what we like about scikit-learn routines is that they tend to be “fire-and-forget”, because they reliably run on a huge diversity of inputs: sparse inputs, missing values, different data types. This diversity of inputs is compounded by a diversity of modeling choices: different losses, sample weights…
Each release of scikit-learn extends the toolbox, sometimes by completing the combinatorial of options and data types rather than adding new estimators. Release 1.9 was a real consolidation in this respect:
Tree-based models
-
Native missing-value support in RandomForestRegressor when minimizing the absolute error criterion
-
Support of missing-values for tree-based models monotonic constraints
-
Improved the statistical correctness of fitting with sample weights in HistGradientBoosting, RandomForest and ExtraTree (having exact support of sample weights in complex pipelines is challenging)
Linear models
-
Logistic regression can use natively float32, thus removing memory pressure
-
Multi-Task linear models support fitting on sparse X and sample weights
-
More stable and faster
RidgeCVandRidgeClassifierCV -
Gap safe screening of features for very fast fitting of sparse squared-loss regressors
Other models
-
Sample weight support in minibatch kmeans (a very scalable clustering)
-
Numeric stability of
yeo-johnsonin thepreprocessing.PowerTransformer -
Faster Spectral embedding
Staying up to date with the ecosystem
Scikit-learn can now return sparse arrays, rather than sparse matrices. Indeed, scipy is slowly de-emphasizing sparse matrices, which often surprise users with their behavior that depart from arrays.
Increasing support for GPU
Scikit-learn is increasingly gaining support for optimized compute backends, which enables it, for instance, to run on GPUs. The challenge (and the value) is the incredible diversity of estimators and usecases supported by scikit-learn, and the package is progressively adding backend support in more and more places.
In the 1.9 release, the major features to gain GPU support were:
- Logistic regression and Poisson regression with LBFGS solver
- More metrics (eg average precision score, …)
- Nystroem kernel approximation
See the docs for all details on how to use the compute backends and which estimator support them.
PS: the user experience is currently not as good as with the default compute backend (numpy). But adding and improving GPU support (with the “array API”) is a good place for talented volunteers to help move the project forward.
Acknowledgements
Scikit-learn is the work of many contributors, with people volunteering their time as well as financial sponsors – see the funding page.